Abstract
A research team, affiliated with UNIST has unveiled a novel AI system, capable of grading and providing detailed feedback on even the most untidy handwritten math answers-much like a human instructor.
Led by Professor Taehwan Kim of UNIST Graduate School of Artificial Intelligence and Professor Sungahn Ko of POSTECH, the team announced the development of VEHME (Vision-Language Model for Evaluating Handwritten Mathematics Expressions), an AI model designed specifically to evaluate complex handwritten mathematics expressions.
Automated grading of open-ended math problems has traditionally been a labor-intensive and time-consuming process in classrooms. The challenge arises from the wide variety of answer formats, including equations, graphs, and diagrams, as well as differences in handwriting styles and how students organize their answers. Developing an AI, capable of accurately understanding and evaluating such unstructured, diverse content has remained a major obstacle.
VEHME approaches this problem by mimicking how a human grader works-carefully analyzing the position and meaning of each element within the problem and solution to identify mistakes.
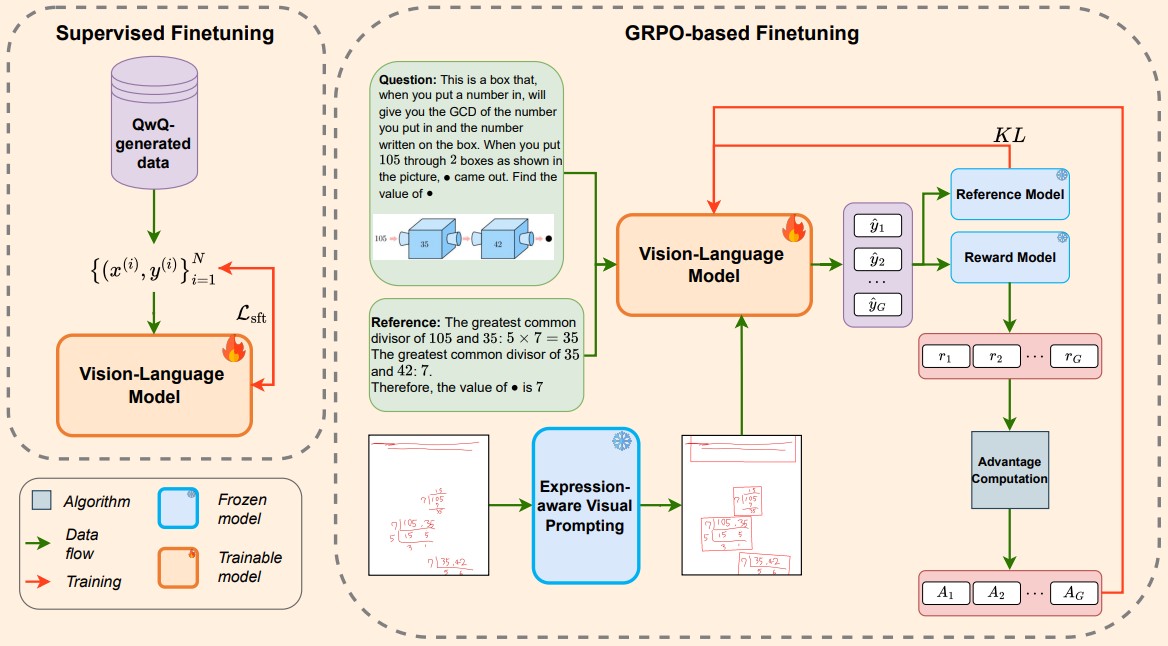 Figure 1. A schematic illustration, describing the overview of VEHME overview.
Figure 1. A schematic illustration, describing the overview of VEHME overview.
In tests covering a broad spectrum-from calculus to elementary arithmetic-VEHME achieved accuracy levels comparable to large proprietary models such as GPT-4o and Gemini 2.0 Flash, despite being a more lightweight and efficient model. Remarkably, VEHME even outperformed commercial models in challenging cases involving heavily rotated or poorly written answers, demonstrating more reliable error detection. While models like GPT-4 and Gemini contain hundreds of billions of parameters, VEHME operates with just 7 billion, illustrating that high performance is attainable without enormous computational resources.
This advancement was made possible through a specialized visual prompting technology called Expression-aware Visual Prompting Module (EVPM), combined with a two-stage training process. EVPM enables VEHME to understand complex, multi-line expressions by virtually "boxing" them, ensuring the model maintains awareness of the problem layout. The second training stage not only helps VEHME recognize correct answers but also equips it to explain where and why errors occur during problem-solving.
Given the scarcity of high-quality handwritten datasets with detailed error annotations, the team generated synthetic training data using a large language model (QwQ-32B), which significantly improved VEHME's learning and evaluation capabilities.
Most importantly, VEHME is open-source and freely accessible, making it a practical tool for schools and researchers interested in adopting or enhancing the system.
Professor Taehwan Kim said, "Grading handwritten math answers is one of the most challenging tasks in educational AI, requiring a nuanced understanding of both images and language. VEHME's ability to follow complex solution steps and accurately identify mistakes marks an important step toward practical classroom applications." He added, "Our EVPM technology can automatically interpret complex visual information, which has potential uses beyond education-such as document processing, technical drawing analysis, and digital archiving of handwritten records."
This research was supported by the Ministry of Science and ICT (MSIT), the National Research Foundation of Korea (NRF), and the Institute for Information & Communications Technology Planning & Evaluation (IITP). The findings have been accepted for presentation at the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025), a leading international conference on empirical natural language processing, which was held from November 5 to 9 in Suzhou, China.
Journal Reference
Thu Phuong Nguyen, Duc M. Nguyen, Hyotaek Jeon, et al., "VEHME: A Vision-Language Model For Evaluating Handwritten Mathematics Expressions," EMNLP '25, (2025).





