Australians are among the most anxious in the world about artificial intelligence (AI).
Authors
- T.J. Thomson
Associate Professor of Visual Communication & Digital Media, RMIT University
- Daniel Angus
Professor of Digital Communication, Director of QUT Digital Media Research Centre, Queensland University of Technology
- Jake Goldenfein
Associate Professor, Melbourne Law School, The University of Melbourne
- Kylie Pappalardo
Associate Professor, School of Law, Queensland University of Technology
This anxiety is driven by fears AI is used to spread misinformation and scam people, anxiety over job losses , and the fact AI companies are training their models on others' expertise and creative works without compensation.
AI companies have used pirated books and articles , and routinely send bots across the web to systematically scrape content for their models to learn from. That content may come from social media platforms such as Reddit, university repositories of academic work, and authoritative publications like news outlets .
In the past, online scraping was subject to a kind of detente. Although scraping may sometimes have been technically illegal, it was needed to make the internet work. For instance, without scraping there would be no Google . Website owners were OK with scraping because it made their content more available, according with the vision of the " open web ".
Under these conditions, scraping was managed through principles such as respect, recognition, and reciprocity. In the context of AI, those are now faltering.
A new online landscape
Many news outlets are now blocking web scrapers . Creators are choosing not to use certain platforms or are posting less.
Barriers are being put in place across the open web. When only some can afford to pay to access news and information, then democracy, scientific innovation and creative communities are all harmed.
Exceptions to copyright infringement, such as fair dealing for research or study , were legislated long before generative AI became publicly available. These exceptions are no longer fit for purpose in an AI age.
The Australian government has ruled out a new copyright exception for text and data mining. This signals a commitment to supporting Australia's creative industries, but leaves great uncertainty about how creative content can be managed legally and at scale now that AI companies are crawling the web.
In response, the international nonprofit Creative Commons has proposed a new voluntary framework: CC Signals .
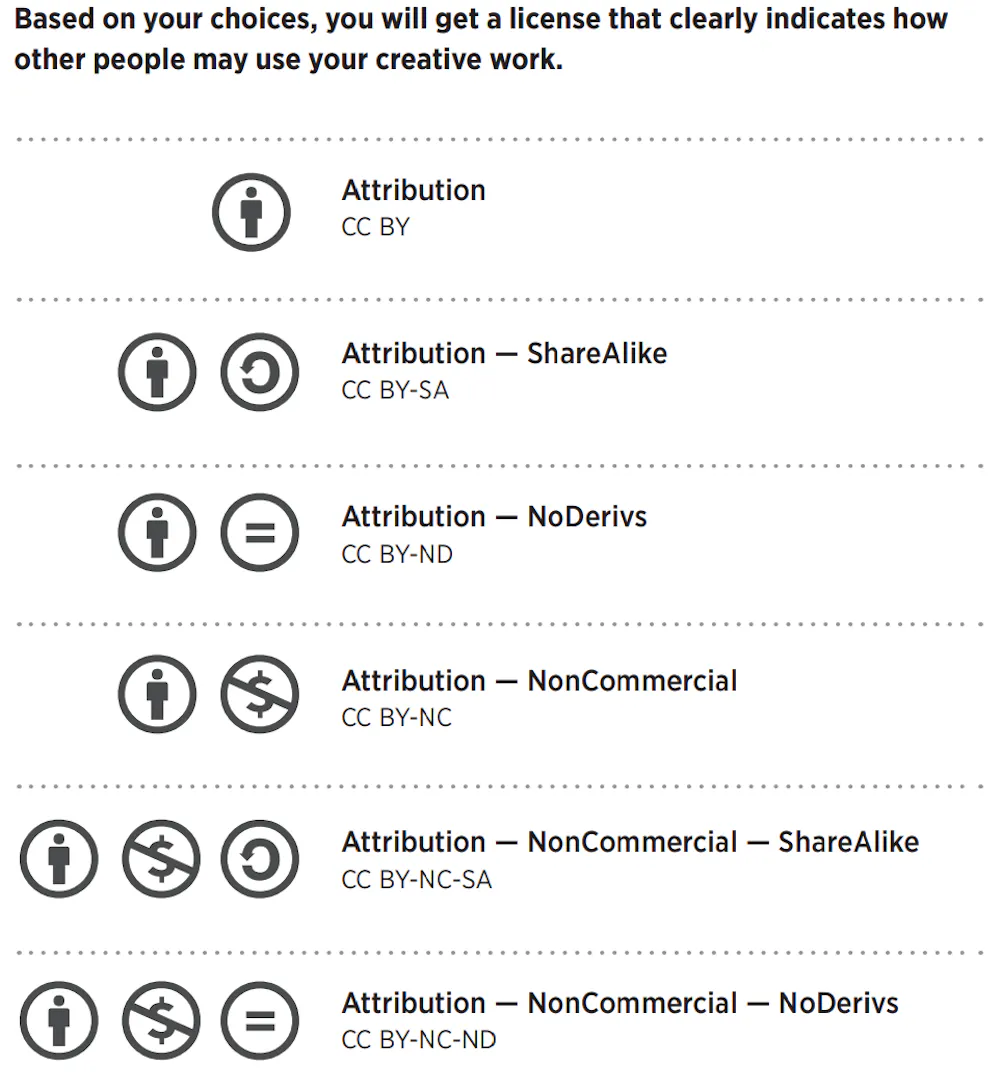
Creative Commons licences allow creators to share content and specify how it can be used. All licences require credit to acknowledge the source, but various additional restrictions can be applied. Creators can ask others not to modify their work, or not to use it for commercial purposes. For example, The Conversation's articles are available for reuse under a CC BY-ND licence , which means they must be credited to the source and must not be remixed, transformed, or built upon.
How would CC Signals work?
The proposed CC Signals framework lets creators decide if or how they want their material to be used by machines. It aims to strike a balance between responsible AI use and not stifling innovation, and is based on the principles of consent, compensation, and credit.
Simplistically, CC Signals work by allowing a "declaring party" - such as a news website - to attach machine-readable instructions to a body of content. These instructions specify what combinations of machine uses are permitted, and under what conditions.
CC Signals are standardised, and both humans and machines can understand them.
This proposal arrives at a moment that closely mirrors the early days of the web, when norms around automated access (crawling and scraping) were still being worked out in practice rather than law.
A useful historical parallel is robots.txt, a simple file web hosts use to signal which parts of a site can be accessed by the bots that crawl the web and look for content. It was never enforceable, but it became widely adopted because it provided a clear, standardised way to communicate expectations between content hosts and developers.
CC Signals could operate in much the same spirit. But, as with any system, it has potential benefits as well as drawbacks.
The pros
The framework provides more nuance and flexibility than the current scrape/don't scrape environment we're in. It offers creators more control over the use of their content.
It also has the potential to affect how much high-quality content is available for scraping. Without access to high-quality data, AI's biases are exacerbated and make the technology less useful .
The framework might also benefit smaller players who don't have the bargaining power to negotiate with big tech companies but who, nonetheless, desire remuneration, credit, or visibility for their work.
The cons
The greatest challenge with CC Signals is likely to be a practical one - how to calculate, and then enforce, the monetary or in-kind support required by some of the signals.
This is also a major sticking point with content industry proposals for collective licensing schemes for AI. Calculating and distributing licence fees for the thousands, if not millions, of internet works that are accessed by generative AI systems around the world is a logistical nightmare.
Creative Commons has said it plans to produce best-practice guides for how to make contributions and give credit under the CC Signals. But this work is still in progress.
Where to from here?
Creative Commons asserts that the CC Signals framework is not so much a legal tool as an attempt to define "manners for machines". Manners is a good way to look at this.
The legal and practical hurdles to implementing effective copyright management for AI systems are huge. But we should be open to new ideas and frameworks that foreground respect and recognition for creators without shutting down important technological developments.
CC Signals is an imperfect framework, but it is a start. Hopefully there are more to come.
![]()
T.J. Thomson receives funding from the Australian Research Council. He is an affiliate with the ARC Centre of Excellence for Automated Decision Making & Society.
Daniel Angus receives funding from the Australian Research Council through Linkage Project LP190101051 'Young Australians and the Promotion of Alcohol on Social Media'. He is a Chief Investigator with the ARC Centre of Excellence for Automated Decision Making & Society.
Jake Goldenfein receives funding from the Australian Research Council through the Centre of Excellence for Automated Decision-Making and Society and the Discovery Project 'AI and the Future of Academic Research and Publishing'.
Kylie Pappalardo receives funding from the Australian Research Council through a DECRA Fellowship (DE210100525). She is an Associate Investigator with the ARC Centre of Excellence for Automated Decision Making & Society. Kylie sits on the Board of the Australian Digital Alliance and on the Australian Government Copyright and AI Reference Group (CAIRG).





