At the outset of the global pandemic in March 2020, Svitlana Volkova and her colleagues turned to the social media platform Twitter to understand and model the spread of COVID-19 misinformation, which was wrinkling hastily hatched plans to protect people from the disease.
"When adversaries are spreading misinformation, there is always an intent. They are doing it for a reason-to spread fear, make a profit, influence politics," said Volkova, an expert in computational social science and computational linguistics at Pacific Northwest National Laboratory in Richland, Washington, who uses artificial intelligence (AI) techniques to model, predict, and explain human social behavior.
Volkova and her colleagues used natural language processing and deep learning techniques they helped develop over the past several years in collaboration with the Defense Advanced Research Projects Agency, which is also known as DARPA, to reveal how and why different types of misinformation and disinformation spread across social platforms.

Applied to COVID-19, the team found that misinformation that is intended to influence politics and incite fear spreads fastest, such as the erroneous link between the novel coronavirus and the wireless communication technology 5G. This type of understanding, Volkova noted, could be harnessed to inform public health strategies designed to combat false narratives and amplify accurate information.
"You know what knobs to turn," she said, explaining that the machine learning algorithms which power social media platforms can be tweaked to identify and block messages with the intent to spread misinformation. At the same time, she added, policymakers can leverage the research insights to spread messages with accurate information that use language, timing, and accounts known to maximize reach.
The power of nontraditional data
Volkova's work using AI to understand the flow of COVID-19 information on social media builds on a stack of research she and her colleagues have produced over the past decade. The research focuses on how publicly available data from sources, such as social media, search engines, and traffic patterns, can be used to model and explain human behavior and improve the accuracy of AI models.
"It's really impossible to get a sense of everything that is happening at the scale we need for modeling human behavior utilizing traditional data sources," she said. "But if you move to the nontraditional data sources, for example mobile data or open social media data, you can have a hand on the pulse."
This field of research is young and rapidly evolving. It is all made possible by the wealth of real-time data generated by people and captured by computers, noted Tim Weninger, a professor of engineering in the Department of Computer Science and Engineering at the University of Notre Dame in Indiana who has known Volkova since graduate school and collaborated with her on the DARPA projects.
The techniques, for example, enable researchers to understand real-time public response to public policies, such as stay-at-home orders used to limit disease spread. Researchers can also slice and dice the data to see how the response varies across states, genders, age groups, and other characteristics that can be learned with algorithms trained on data about how these different populations express themselves on social media. These insights, in turn, can be used to improve models and inform public policy.
"Svitlana is a leader in this new type of computational social science research where you can ask questions and understand the traits and behaviors of people in response to external events," Weninger said.
Volkova's recognized expertise at the interface of open-source data and AI to improve modeling helped her secure one of seven competitively selected spots to co-organize a National Academy of Sciences workshop. The workshop explored how environmental health tools, technologies and methodologies, and traditional and nontraditional data sources can inform real-time public health decision-making about infectious disease outbreaks, epidemics, and pandemics.
During the workshop earlier this month, Volkova chaired a session on the use of AI in public health and the value of real-time, nontraditional data sources to improve infectious disease modeling and public health decision-making.
Weninger noted that such techniques were sorely lacking from most models the epidemiological community used to predict the path of COVID-19 in March 2020, which showed a curve with a singular peak in case counts that gradually diminished over time.
"They're not anywhere close to what actually happened," he said. "What these models failed to realize is human behavior. They didn't have that human variable in the equation. What we have to realize is that these ebbs and flows, where there is a spike that went away and then another spike again that went away, happened yes, because of the virus, but also because of how humans were dealing with it."
Real-time surveillance
Volkova first turned to open data captured by computers to glean insights about disease spread while in graduate school as a Fulbright scholar at Kansas State University in 2008. There, she started building tools for conducting real-time surveillance of infectious disease threats posed by viruses that could jump from animals to humans. She did this by building and training AI models to crawl the internet for news articles and other mentions of specific animal diseases.
"That was a big deal 10 years ago, where we developed algorithms that go and get this data from the public to do surveillance-to see, okay, in this location there have been reports of this specific disease," Volkova said. Today, she added, that type of real-time surveillance is routine, automatic, and constant to monitor for threats, such as the proliferation and use of weapons of mass destruction.
After graduate school, Volkova headed to Johns Hopkins University in Baltimore, Maryland, for her PhD in computer science and natural language processing, where she honed techniques on how to infer what people are thinking and feeling from the language they use on social media.
"Broadly, I see myself as a person who's interested in studying human social behavior and interactions at scale from public data," she said.
The key to doing this type of research is having the capability to make sense of the wealth of data generated by people and that is available to the public from sources ranging from social media, search engines and news articles, to traffic patterns and satellite imagery.
"First, we make sense of the data. Second, we make this data useful with an umbrella of AI powered methods," Volkova said.
From a tweet to a representation
In 2017, Volkova and her colleagues published research showing AI models built on open-source human behavior data gleaned from social media predicted the spread of influenza-like illness in specific areas, as well as AI models trained on historical data, such as hospital visits. In addition, the models with both real-time human behavior data and historical data significantly outperformed the models trained solely on historical data.
The research leveraged Volkova's natural language processing techniques to understand how the emotions and opinions people express on social media reflect their health. She and her colleagues found that neutral opinions and sadness were expressed most during periods of high influenza-like illness. During low illness periods, positive opinion, anger, and surprise were expressed more.
This aspect of her research is the sense-making of the data.
"To make sense of the data, we have to go from a completely unstructured, human-generated tweet into something that I can feed into the model," she explained. "I cannot just send the sentence. The model won't be able to do much with the sentence. I convert that tweet into a representation."
Once converted into a representation, the tweet data can be fed into an AI model. This part of the process, she noted, is what makes the data useful.
"AI should help to solve a downstream task to the end user. It should be predictive, and you can develop many models to operate in this representation space. You can teach the model in many different ways to predict reactions, emotions, demographics, and misinformation."
Unknown unknowns
Volkova and her colleagues used three years of data to train the models for their 2017 influenza paper. When COVID-19 hit in March 2020, the modeling community was unprepared, she said. The Centers for Disease Control and Prevention, for example, used about a dozen epidemiological models from academia and industry to forecast the path of the virus. The models failed to form a consensus and most made predictions that were no better than asking a random person on the street to make a guess, Volkova said.
Nearly all these models incorporated data, such as case counts, testing results, and the availability of hospital beds and ventilators. They also accounted for the predicted impact of public health policies, such as stay-at-home orders and mandates to wear facial coverings in public spaces. What the models missed, Volkova said, is real-world, real-time human behavior data.
"If you don't know whether people are actually wearing masks-if you don't know whether people are complying and staying home-your models are so wrong," she said.
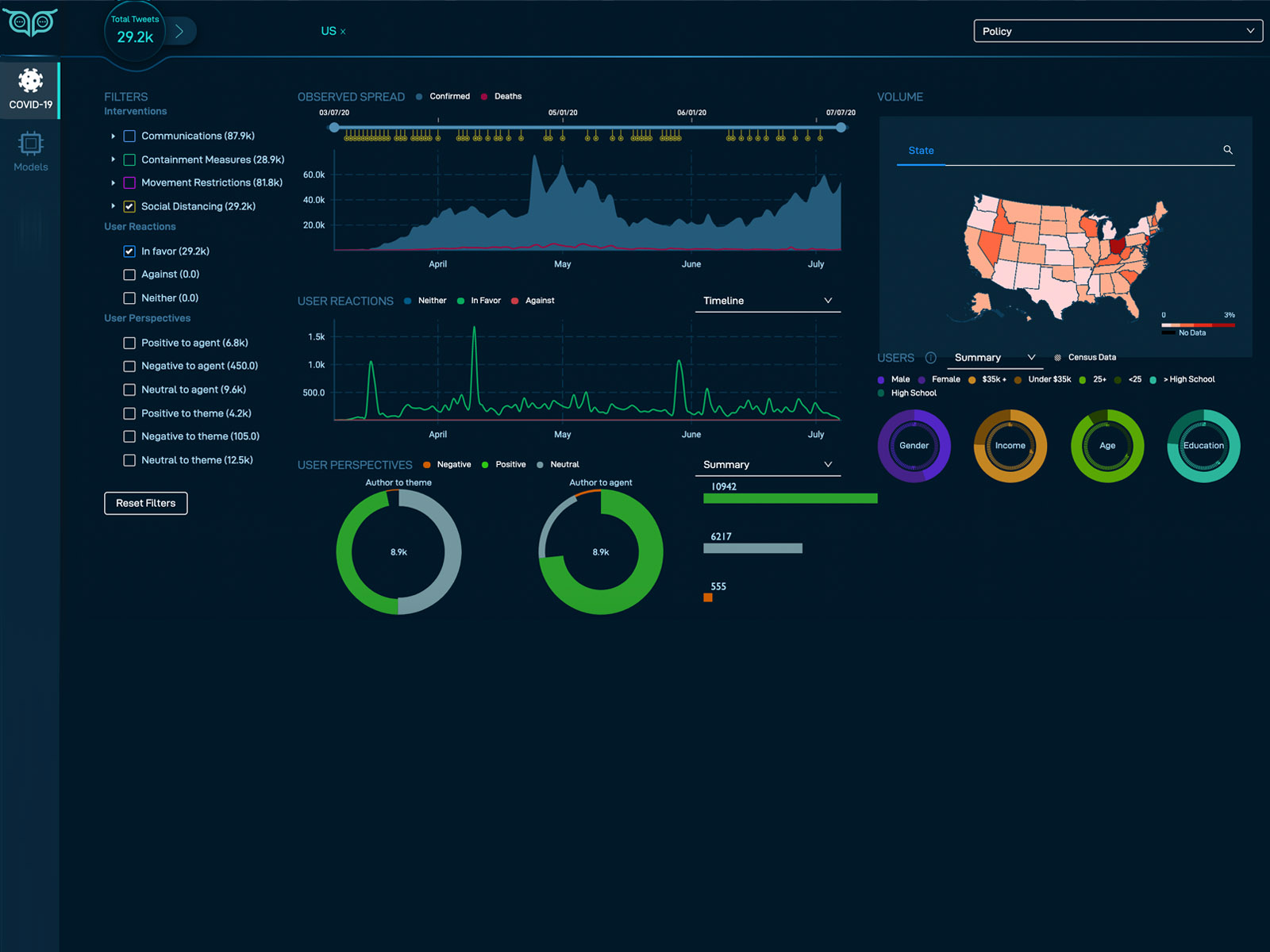
To help fill this gap, Volkova and her PNNL colleagues developed an online tool called WatchOwl, a decision intelligence capability that uses deep learning and natural language processing techniques to understand how people in the United States respond on Twitter to non-pharmaceutical interventions, such as mask wearing, social distancing, and compliance with stay-at-home orders.
The tool, which is available online, has interactive visual analytics that allow users to slice and dice the data to understand, for example, female mask compliance in Florida.
At the National Academy of Sciences workshop, Volkova's session on real-time, open-source data featured AI-driven tools, such as WatchOwl, and included a discussion about how the data insights could inform public policy and decision-making when the next pandemic hits.
"I like to talk about it from the perspective of unknown unknowns," Volkova said of the efforts to incorporate nontraditional data into models. "We don't know what we don't know and when you are trying to model a phenomenon, knowing everything is required, but it's impossible. There are always unknown unknowns. By going and looking into nontraditional data sources that are real time, you can have fewer unknown unknowns."





