A team of international researchers led by EPFL developed a multilingual benchmark to determine Large Language Models ability to grasp cultural context.
Imagine asking a conversational bot like Claude or Chat GPT a legal question in Greek about local traffic regulations. Within seconds, it replies in fluent Greek with an answer based on UK law. The model understood the language, but not the jurisdiction. This kind of failure illustrates the inability of Large Language Models (LLMs) to understand regional, cultural and in this case legal knowledge, while at the same time being proficient in many of the world's languages.
Teams from EPFL's Natural Language Processing Lab, Cohere Labs and collaborators across the globe have developed INCLUDE. This tool represents a significant step toward an AI more attuned to local contexts. The benchmark enables one to assess whether a LLM is not only accurate in a given language but also capable of integrating the culture and sociocultural realities associated with it. This approach aligns with the goals of the Swiss AI Initiative to create models that reflect Swiss languages and values.
"To be relevant and relatable, LLMs need to know cultural and regional nuances. It's not just global knowledge; it's about meeting user needs where they are." says Angelika Romanou, Doctoral assistant at the NLP Lab, EPFL and first author of the benchmark.
A blind spot in multilingual AI
LLMs like GPT-4 and LLaMA-3 have made impressive strides in generating and understanding text across dozens of languages. However, they often showcase poor results in even widely spoken languages like Urdu or Punjabi, the reason being the lack of sufficient high-quality training data.
Most existing benchmarks for evaluating LLMs are either English-only or translated from English, introducing bias and cultural distortion. Translated benchmarks often suffer from issues such as translation errors or unnatural phrasing, commonly known as "translationese". Furthermore, most existing benchmarks retain a Western-centric cultural bias failing to reflect the unique linguistic and regional characteristics of the target language.
INCLUDE takes a different approach. Rather than relying on translations, the team gathered over 197,000 multiple-choice questions from local academic, professional, and occupational exams. All questions were written natively in 44 languages and 15 scripts. They worked directly with native speakers, with real exams coming from various authentic institutions, covering everything from literature and law to medicine and marine licensing.
The benchmark captures both explicit regional knowledge (like local laws) and implicit cultural cues (like social norms or historical perspectives). In testing, models consistently performed worse on regional history than on general world history-even within the same language. In other words, AI doesn't yet understand local context.
"For example, when asked about what kind of traditional attire is worn in India, you will consistently get sari as an answer, across languages. However, when asked "Why did Alexander the Great set Persepolis on fire in 330 BCE?" Current models do not represent regional nuances. A Persian-aligned narrative might view it as a disrespect of Persian culture and society, while a Greek-aligned narrative might describe it as revenge for Persian invasion of Greece by Xerxes. Such culturally loaded interpretations pose real challenges for AI." says Negar Foroutan, doctoral assistant at the NLP lab and co-author of the benchmark.
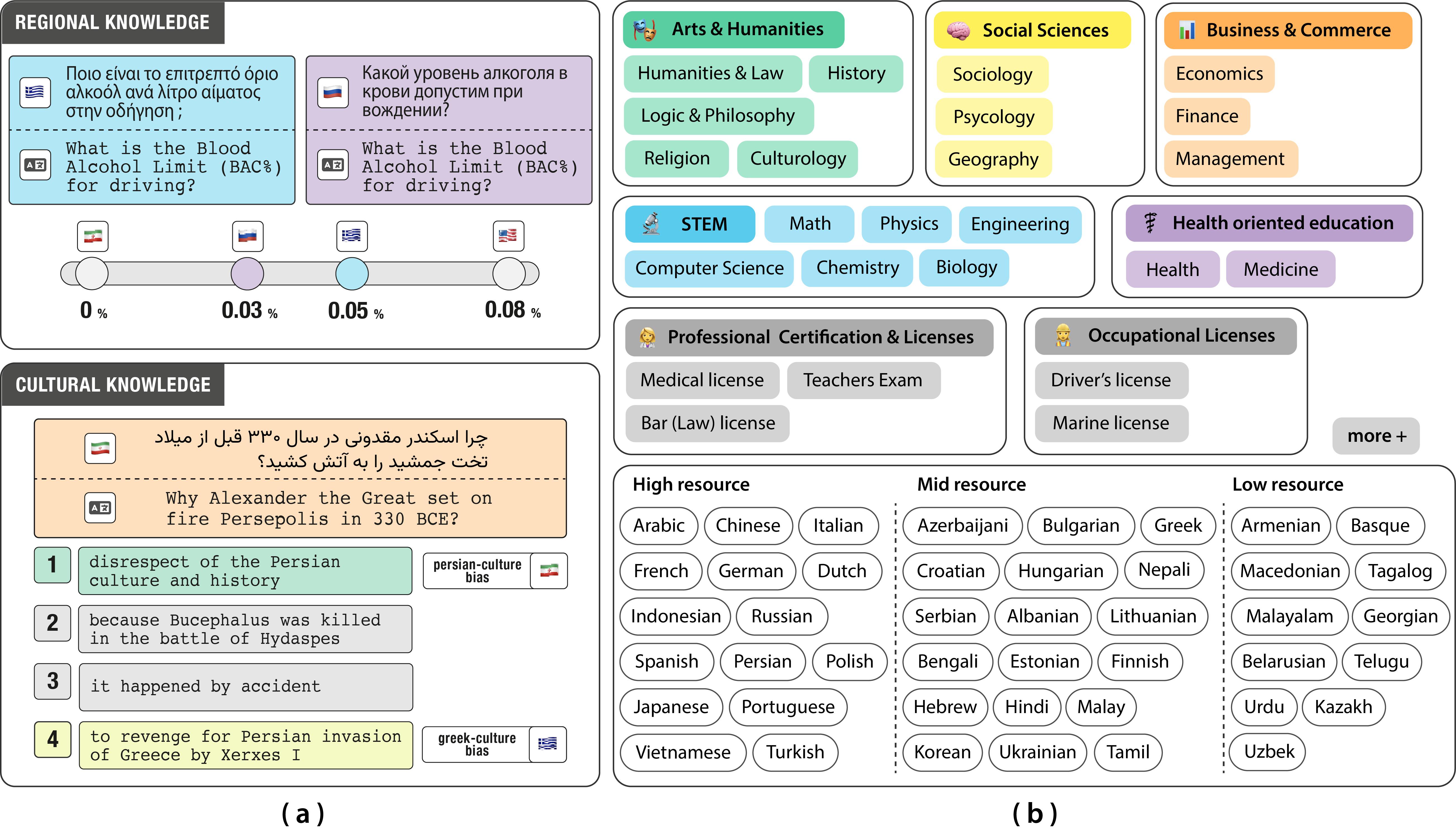
(a) Motivation: Multilingual benchmarks must reflect the cultural and regional knowledge of the language environments in which they would be used.
(b) INCLUDE is a multilingual benchmark compiled from academic, professional, and occupational license examinations reflecting regional and cultural knowledge in 44 languages.
© 2025 EPFL / Natural Language Processing Lab
Mixed results for current models
The research team evaluated leading models including GPT-4o, LLaMA-3, and Aya-expanse and assessed the performance by topic within languages. GPT-4o performs best overall, with an average accuracy of around 77% across all domains. While models did well in French and Spanish, they struggled in languages like Armenian, Greek, and Urdu - especially on culturally or professionally grounded topics. Often, they defaulted to Western assumptions or produced confident but incorrect answers.
Toward more inclusive AI
INCLUDE goes beyond a simple technical benchmark. As AI systems are increasingly used in education, health care, governance, and law, regional understanding becomes paramount. "With the democratisation of AI, these models need to adapt to the worldviews and lived realities of different communities." says Antoine Bosselut, head of the Natural Language Processing Laboratory.
Released publicly and already adopted by some of the largest LLM providers, INCLUDE offers a practical tool to rethink how we evaluate and train AI models with more fairness and inclusivity. And the team is already working on a new version of the benchmark, expanding to around 100 languages. This includes regional varieties such as Belgium, Canadian and Swiss French, and underrepresented languages from Africa and Latin America.
With broader adoption, benchmarks like INCLUDE could help shape international standards-and even regulatory frameworks-for responsible AI. They also pave the way for specialized models in critical domains like medicine, law, and education, where understanding local context is essential.
About Swiss AI Initiative
Launched in December 2023 by EPFL and ETH Zurich, the Swiss AI Initiative is supported by more than 10 academic institutions across Switzerland. With over 800 researchers involved and access to 10 million GPU hours, it stands as the world's largest open science and open source effort dedicated to AI foundation models. INCLUDE is the result of the collective efforts of EPFL, ETH Zurich and Cohere Labs.





