A study from EPFL reveals why humans excel at recognizing objects from fragments while AI struggles, highlighting the critical role of contour integration in human vision.
Every day, we effortlessly recognize friends in a crowd or identify familiar shapes even if they are partly hidden. Our brains piece together fragments into whole objects, filling in the blanks to make sense of an often chaotic world.
This ability is called "contour integration" and is something even the smartest AI systems still find difficult to do. Despite the remarkable achievements of artificial intelligence in image recognition, AIs still struggle to generalize from incomplete or broken visual information.
When objects are partly hidden, erased, or broken into fragments, most AI models falter, misclassify, or give up. This can be a serious problem in real life, given our increasing reliance on AI for real-world applications such as self-driving cars, prosthetics, and robotics.
The EPFL NeuroAI Lab, led by Martin Schrimpf, set out to systematically compare how people and AI handle visual puzzles. Ben Lönnqvist, an EDNE graduate student and lead author of the study, collaborated with Michael Herzog's Laboratory of Psychophysics to develop a series of recognition tests where both humans and more than 1,000 artificial neural networks had to identify objects with missing or fragmented outlines. Their results show that when it comes to contour integration, humans consistently outperform state-of-the-art AI, and why.
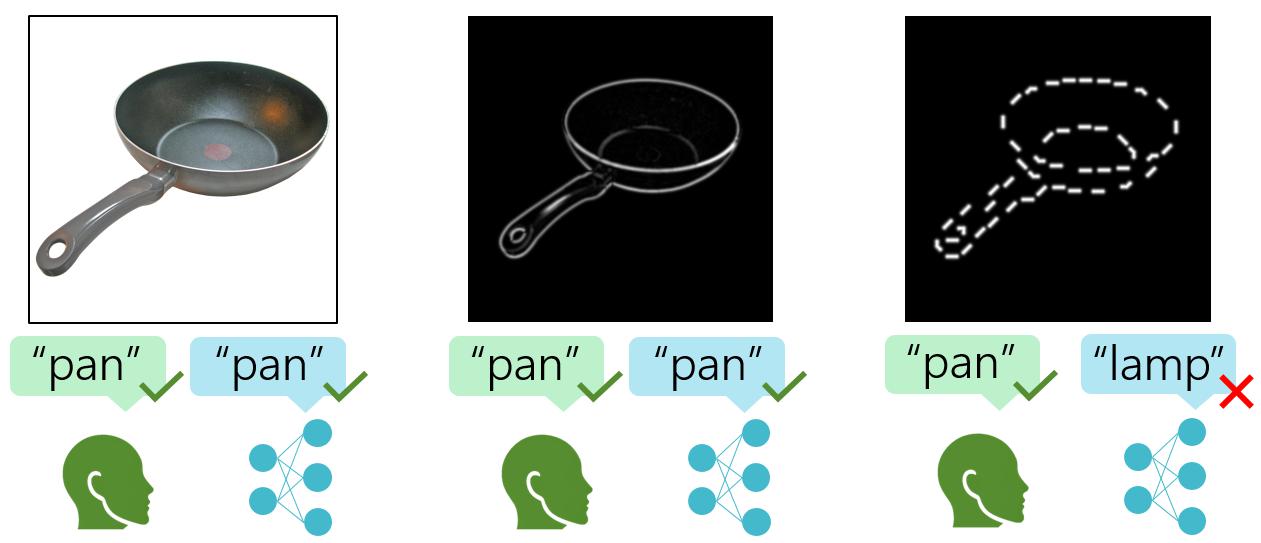
The research was presented at the 2025 International Conference on Machine Learning (ICML).
The team set up a a lab-based object recognition test with fifty volunteers. The participants viewed images of everyday items such as cups, hats, pans etc whose outlines were systematically erased or broken up into segments. Sometimes, only 35% of an object's contours remained visible. In parallel, the team gave the same task to over 1,000 AI models, including some of the most powerful systems available.
The experiment covered 20 different conditions, varying the type and amount of visual information. The team compared performance across these conditions, measuring accuracy and analyzing how both humans and machines responded to increasingly difficult visual puzzles.
Humans proved remarkably robust, often scoring 50% accuracy even when most of an object's outline was missing. AI models, by contrast, tended to collapse to random guessing under the same circumstances. Only models trained on billions of images came close to human-like performance-and even then, they had to be specifically adapted to the study's images.
Digging deeper, the researchers found that humans show a natural preference for recognizing objects when fragmented parts point in the same direction, which the team referred to as "integration bias". AI models that were trained to develop a similar bias performed better when challenged with image distortions. Training AI systems specifically designed for integrating contours boosted their accuracy and also made them focus more on an object's shape, rather than surface texture.
These results suggest that contour integration is not a hardwired trait but instead can be learned from experience. For industries that rely on computer vision, such as self-driving cars or medical imaging, building AI that sees the world more like we do could mean safer, more reliable technology.
The work also shows that the best way to close the gap isn't by tinkering with AI architectures but by giving machines a more "human-like" visual diet, including multiple real-world images where objects are often partly hidden.





