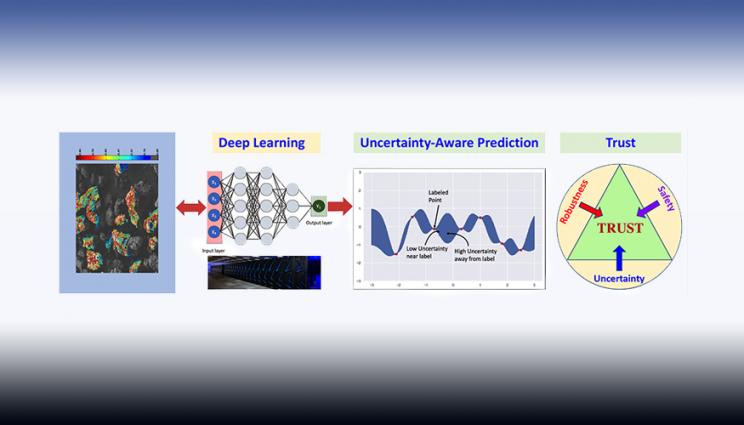
In a paper accepted into the 2020 International Conference on Machine Learning, Lawrence Livermore National Laboratory researchers describe a new "Mix-n-Match" method for calibrating uncertainty of deep learning models. Uncertainty qualification is an important factor for building trust in predictive models for critical applications where accuracy and confidence are essential.
Two papers featuring Lawrence Livermore National Laboratory (LLNL) scientists were accepted in the 2020 International Conference on Machine Learning (ICML), one of the world's premier conferences of its kind.
The first, authored by three LLNL researchers, describes a new "mix-n-match" method for calibrating uncertainty of deep learning models. Uncertainty qualification is an important factor for building trust in predictive models for critical applications where accuracy and confidence are essential, according to Lab scientists.
In the paper, the team points out major flaws in existing methods for evaluating calibration quality, showing that evaluation metrics can be misleading or unreliable. They also found that no single method available could calibrate uncertainties while still maintaining key properties of dependable deep learning models: accuracy, data efficiency and expressiveness. To address this, they proposed mix-n-match strategies that employ several operations (ensemble and composition) to produce a calibration method capable of satisfying all three properties and created guidelines for choosing an appropriate calibration method based on available resources.
Lead author Jize Zhang, a postdoc in the Lab's Center for Applied Scientific Computing (CASC), will present the paper at the 37th edition of the conference, which is being held virtually from July 12-18.
"In the machine learning community, much of the focus right now is on improving accuracy and not uncertainty," Zhang said. "I believe our work comes in a timely manner for addressing some flaws and should be a general backbone for the future machine learning systems. Also, I think this work is the first to show how to choose the best method, given the amount of data available and also the complexity of the neural network classifier. With the experiments we've conducted, we show that we get state-of-the-art performance and achieve orders of magnitude enhancement on both data-efficiency and expressive power."
The team applied their mix-n-match method to popular benchmark datasets ImageNet and CIFAR 10/100 and discovered that it significantly improved the uncertainty quality of the neural network classifier over conventional methods. The team is using the approach to reliably optimize Lab-developed feedstock materials, including working on understanding and improving the performance of energetic materials. They are using scanning electron microscopy images to predict the material properties and how they would behave in a mechanical test.
"We not only need a machine learning model to determine how these materials will perform, but we also need to know how confident the models are in making the predictions - right now, there's not a good way to do that accurately," explained Yong Han, co-author and principal investigator of a Laboratory Directed Research and Development (LDRD) Strategic Initiative on applying machine learning to materials science, which funded the work. "So far, the models we have used are overconfident, but with Jize's model, we are getting more accurate about uncertainty. Previously, we thought we had enough data to make good predictions, but now we know that certain predictions are not good enough and that we need to provide more data to raise this confidence level and create a model we can all trust."
Co-author Bhavya Kailkhura said the team's calibration method is "simple and practical" and is meant to complement - not compete with - existing techniques. As it is further developed, it could prove to be a valuable tool for integrating advanced machine learning technology into the pipeline of work at LLNL by improving overall dependability and reliability of machine learning models, he said.
"It is crucial to have this technology we've developed if we want to use machine learning in mission-critical applications," Kailkhura said. "If you have a deep learning network that is doing radiation detection for example, it will be very important for us to know that the tool will not make any incorrect predictions silently. If it sees something unexpected that it has not seen before, that deep learning network should say, 'I have not seen this data, let me not make a prediction on it.' Trust is needed for a technology to be sustainable, and that is what we are focusing on."
Better text-generation through neural networks
Kailkhura is a co-author on the second paper from LLNL accepted by the conference, alongside collaborators at Zhejiang University in China, the University of Illinois, Urbana Champaign, the Alibaba Group and others. The paper focuses on using neural networks to generate more meaningful and relevant text for applications such as chatbots, document summarization and language translation.
"What this paper does is give us a better way to generate new text," said Kailkhura. "An ideal technology should try to understand context to have a conversation and reply in a meaningful way. We have come up with a new algorithm that can generate more exciting, more relevant text, instead of boring text like 'I don't know.' "
Other groups have approached text generation as a forward problem, Kailkhura said, but his team focused on modeling the backward network of mutual information, a measure of the mutual dependence between two random variables. The researchers implemented a "min-max game" or competitive optimization-based approach, in which artificial intelligence agents compete with each other with a goal of generating improved text. This Adversarial Mutual Information framework tightens the lower bound of maximum mutual information, making the language approximations closer to the true objective.
While text-generation application is common in industry, it is rarely used in science, Kailkhura explained. However, it could be used to summarize large amounts of scientific papers or translate publications written in foreign languages to improve scientists' knowledge base.
"I see that this technology has a lot of potential," Kailkhura said. "This is a hammer that could be applied to many different nails. We can now start to think about how this may be used for scientific applications. This will be an exciting direction we will look to in the future."
The work at LLNL also was funded through the LDRD "Exploratory Research on Safe and Trustworthy Machine Learning," led by Kailkhura, in which Lab data scientists have developed adversarial optimization techniques to certify deep learning robustness.
Forefront of machine learning
Researchers said having multiple papers accepted into a prestigious and competitive venue like the ICML shows that LLNL is at the forefront of machine learning.
"We have a very talented and creative team of researchers developing new machine learning approaches for scientific applications, and it is wonderful to see the broader machine learning community recognize the value of their work," said Jeffrey Hittinger, director of CASC. "This recognition not only will further establish them as leaders in their field but will raise the profile of the Lab as a place where exciting research in machine learning is done."
"What we bring to the table is not only advances in machine learning and computer science, but the know-how to apply these emerging techniques to unique application domains," Han added. "That's what makes Livermore really stand out to people working in data science. There is so much opportunity to do impactful work across so many different fields of research."





