Both living creatures and AI-driven machines need to act quickly and adaptively in response to situations. In psychology and neuroscience, behavior can be categorized into two types - habitual (fast and simple but inflexible), and goal-directed (flexible but complex and slower). Daniel Kahneman, who won the Nobel Prize in Economic Sciences, distinguishes between these as System 1 and System 2. However, there is ongoing debate as to whether they are independent and conflicting entities or mutually supportive components.
Scientists from the Okinawa Institute of Science and Technology (OIST) and Microsoft Research Asia in Shanghai have proposed a new AI method in which systems of habitual and goal-directed behaviors learn to help each other. Through computer simulations that mimicked the exploration of a maze, the method quickly adapts to changing environments and also reproduced the behavior of humans and animals after they had been accustomed to a certain environment for a long time.
The study, published in Nature Communications, not only paves the way for the development of systems that adapt quickly and reliably in the burgeoning field of AI, but also provides clues to how we make decisions in the fields of neuroscience and psychology.
The scientists derived a model that integrates habitual and goal-directed systems for learning behavior in AI agents that perform reinforcement learning, a method of learning based on rewards and punishments, based on the theory of "active inference", which has been the focus of much attention recently. In the paper, they created a computer simulation mimicking a task in which mice explore a maze based on visual cues and are rewarded with food when they reach the goal.
They examined how these two systems adapt and integrate while interacting with the environment, showing that they can achieve adaptive behavior quickly. It was observed that the AI agent collected data and improved its own behavior through reinforcement learning.
What our brains prefer
After a long day at work, we usually head home on autopilot (habitual behavior). However, if you have just moved house and are not paying attention, you might find yourself driving back to your old place out of habit. When you catch yourself doing this, you switch gears (goal-directed behavior) and reroute to your new home. Traditionally, these two behaviors are considered to work independently, resulting in behavior being either habitual and fast but inflexible, or goal-directed and flexible but slow.
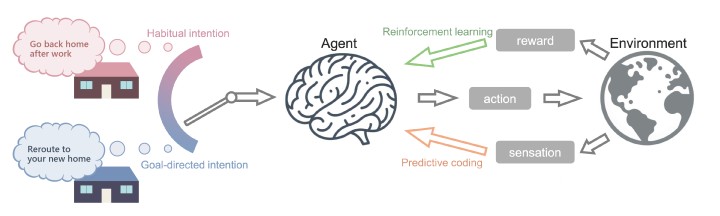
"The automatic transition from goal-directed to habitual behavior during learning is a very famous finding in psychology. Our model and simulations can explain why this happens: The brain would prefer behavior with higher certainty. As learning progresses, habitual behavior becomes less random, thereby increasing certainty. Therefore, the brain prefers to rely on habitual behavior after significant training," Dr. Dongqi Han, a former PhD student at OIST's Cognitive Neurorobotics Research Unit and first author of the paper, explained.
For a new goal that AI has not trained for, it uses an internal model of the environment to plan its actions. It does not need to consider all possible actions but uses a combination of its habitual behaviors, which makes planning more efficient. This challenges traditional AI approaches which require all possible goals to be explicitly included in training for them to be achieved. In this model each desired goal can be achieved without explicit training but by flexibly combining learned knowledge.
"It's important to achieve a kind of balance or trade-off between flexible and habitual behavior," Prof. Jun Tani, head of the Cognitive Neurorobotics Research Unit stated. "There could be many possible ways to achieve a goal, but to consider all possible actions is very costly, therefore goal directed behavior is limited by habitual behavior to narrow down options."
Building better AI
Dr. Han got interested in neuroscience and the gap between artificial and human intelligence when he started working on AI algorithms. "I started thinking about how AI can behave more efficiently and adaptably, like humans. I wanted to understand the underlying mathematical principles and how we can use them to improve AI. That was the motivation for my PhD research."
Understanding the difference between habitual and goal-directed behaviors has important implications, especially in the field of neuroscience, because it can shed light on neurological disorders such as ADHD, OCD, and Parkinson's disease.
"We are exploring the computational principles by which multiple systems in the brain work together. We have also seen that neuromodulators such as dopamine and serotonin play a crucial role in this process," Prof. Kenji Doya, head of the Neural Computation Unit explained. "AI systems developed with inspiration from the brain and proven capable of solving practical problems can serve as valuable tools in understanding what is happening in the brains of humans and animals."
Dr. Han would like to help build better AI that can adapt their behavior to achieve complex goals. "We are very interested in developing AI that have near human abilities when performing everyday tasks, so we want to address this human-AI gap. Our brains have two learning mechanisms, and we need to better understand how they work together to achieve our goal."





