Today, Open Molecules 2025, an unprecedented dataset of molecular simulations, was released to the scientific community, paving the way for development of machine learning tools that can accurately model chemical reactions of real-world complexity for the first time.
This vast resource, produced by a collaboration co-led by Meta and the Department of Energy's Lawrence Berkeley National Laboratory (Berkeley Lab), could transform research for materials science, biology, and energy technologies.
"I think it's going to revolutionize how people do atomistic simulations for chemistry, and to be able to say that with confidence is just so cool," said project co-lead Samuel Blau, a chemist and research scientist at Berkeley Lab. His colleagues on the team hail from six universities, two companies, and two national labs.
"We were super excited to work with the community to build this dataset and see where it will take us in creating new AI models," said Larry Zitnick, research director of Meta's Fundamental AI Research (FAIR) lab.
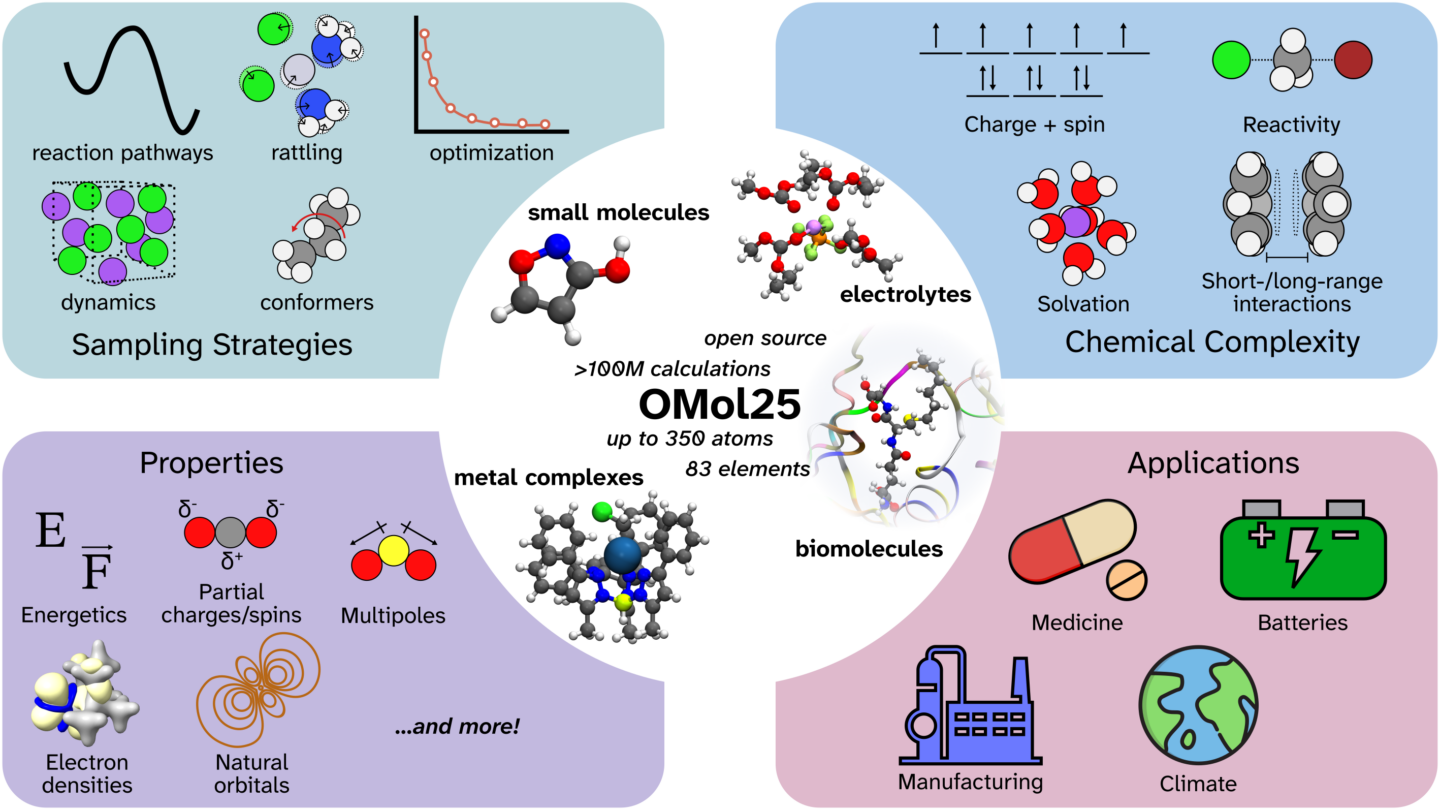
Open Molecules 2025, or OMol25, is a collection of more than 100 million 3D molecular snapshots whose properties have been calculated with density functional theory (DFT). DFT is an incredibly powerful tool for modeling precise details of atomic interactions, allowing scientists to predict the force on each atom and the energy of the system, which in turn dictate the molecular motion and chemical reactions that determine larger-scale properties, such as how the electrolyte reacts in a battery or how a drug binds to a receptor to prevent disease.
The ability to simulate large systems with DFT-level accuracy would help scientists rapidly design new energy storage technologies, new medicines, and beyond. But DFT calculations demand a lot of computing power, and their appetite increases dramatically as the molecules involved get bigger, making it impossible to model scientifically relevant molecular systems and reactions of real-world complexity, even with the largest computational resources.
Recent advances in machine learning offer a way to overcome these limitations. Machine Learned Interatomic Potentials (MLIPs) trained on DFT data can provide predictions of the same caliber 10,000 times faster, unlocking the ability to simulate the large atomic systems that have always been out of reach, while running on standard computing systems. However, the usefulness of an MLIP depends on the amount, quality, and breadth of the data that it has been trained on. Enter OMol25 - the most chemically diverse molecular dataset for training MLIPs ever built.
Building a new resource
Creating OMol25 required an exceptional amount of computing power and DFT expertise. The FAIR team used Meta's massive global network of computing resources to run the millions of DFT simulations, taking advantage of the periods of spare bandwidth when a part of the world was asleep instead of browsing Instagram and Facebook.
Past molecular datasets were limited to simulations with 20-30 total atoms on average and only a handful of well-behaved elements. The configurations in OMol25 are ten times larger and substantially more complex, with up to 350 atoms from across most of the periodic table including heavy elements and metals which are challenging to simulate accurately. The datapoints capture a huge range of interactions and internal molecular dynamics involving both organic and inorganic molecules.
"OMol25 cost six billion CPU hours, over ten times more than any previous dataset. To put that computational demand in perspective, it would take you over 50 years to run these calculations with 1,000 typical laptops," said Blau.
A leap forward in AI models
Scientists around the world can now begin training their own MLIPs on OMol25. They can also use the FAIR lab's open-access universal model, also released today. The universal model was trained on OMol25 and FAIR lab's other open-source datasets - which they have been releasing since 2020 - and is designed to work "out of the box" for many applications. However, the universal model and any other MLIPs trained with the dataset are expected to improve over time, as researchers learn how to best leverage the vast amount of data at their fingertips.
To measure and track model performance, the collaboration has provided evaluations, which are sets of challenges that analyze how well a model can accurately complete useful tasks. The team strove to develop exceptionally thorough evaluations to give fellow researchers more confidence in the capabilities of MLIPs trained on the dataset. "Once you get to chemistry like atomic bonds breaking and reforming and molecules with variable charges and spins, researchers are going to be rightfully skeptical of any ML tool," said Blau, who also played a large role in this component of the project.
Evaluations also drive innovation through friendly competition, as the results are ranked publicly. Potential users can see which ones run smoothly and developers can see how their model stacks up against others.
"Better benchmarks and evaluations have been essential for progress and advancing many fields of ML," added OMol25 team member Aditi Krishnapriyan, a faculty scientist in Berkeley Lab's Applied Mathematics and Computational Research Division, and assistant professor of Chemical and Biomolecular Engineering and Electrical Engineering and Computer Sciences at UC Berkeley. Krishnapriyan assisted in the evaluations and developing a subset of the chemical simulations.
"Trust is especially critical here because scientists need to rely on these models to produce physically sound results that translate to and can be used for scientific research," said Krishnapriyan.
By the community, for the community
OMol25 was created by scientists to fill an unmet need for their community, and the ethos of collaboration is woven throughout all aspects of the project. To curate the content in OMol25, the team started with past datasets made by others, as these represent molecular configurations and reactions that are important to researchers in different chemistry specialties. Then they performed more sophisticated simulations on these snapshots using their advanced DFT capabilities. Next, they looked to see what major types of chemistry had not been captured previously, and tried to fill the gap.
Three-quarters of the dataset is composed of this new content, divided into three major focus areas: biomolecules, electrolytes, and metal complexes (molecules arranged around a central metal ion). There is still a need for snapshots involving polymers - large molecules made of repeating units called monomers. This will be addressed by the upcoming Open Polymer data, a complementary project that also includes collaborators from Lawrence Livermore National Laboratory.
The OMol25 team itself was brought together by the branching connections of the STEM community that span academia and industry. Blau and co-leader Brandon Wood, a research scientist in FAIR, met while working in the lab of Kristin Persson, a Berkeley Lab and UC Berkeley researcher who leads the Materials Project. Wood, Blau, and Larry Zitnick, the FAIR chemistry research director, joined forces on the OMol25 project in Fall 2023. Together, they recruited scientists they admired from UC Berkeley, Carnegie Mellon, New York University, Princeton University, Stanford University, the University of Cambridge, Los Alamos National Laboratory, and Genentech.
"This open dataset is the result of a fantastic team effort, and we can't wait to see how the community leverages it to explore new directions in AI modeling," said Wood.
"It was really exciting to come together to push forward the capabilities available to humanity," added Blau.
Blau's work on OMol25 was funded by Berkeley Lab's Laboratory Directed Research and Development (LDRD) program. His contributions to the electrolyte modeling portion of the dataset were funded by the Energy Storage Research Alliance, a battery research initiative of the DOE Office of Science. Krishnapriyan's work was funded by the DOE Office of Science, as part of the Center for Ionomer-based Water Electrolysis.





